Monitoring your API's performance
You worked hard to build a great front-end web or mobile app. But your customers will hate it if your back-end doesn’t respond, or takes too long. API performance is critical to the customer experience. Effective monitoring enables you to detect and fix problems before your customers are affected.
On 20 July, apiConnections held our first in-person meetup in Singapore for over two years. Rajalakshmi "Raji" Srinivasan, Director, Product Management, Site24x7, ZohoCorp presented best practices in monitoring API performance.
Here is a summary of Raji's presentation.
Key Takeaways:
- Why API performance affects the customer experience
- The key pillars of API observability
- Monitoring what’s important: response time, application workflow, downtime
- How to monitor secured API endpoints
Topics covered:
- APIs and digital transformation
- Observability vs Monitoring
- DevOps and SRE and Observability
- API stack in a cloud architecture
- Pillars of Observability
- Achieving Observability in an API stack
Digital transformation and the user experience
The move to digital interactions has accelerated dramatically in the last two years, to the point that digital is now the predominant method for companies to communicate with their customers.
Organisations now recognise that they cannot simply "lift and shift" their operations to the digital, cloud-native environment.
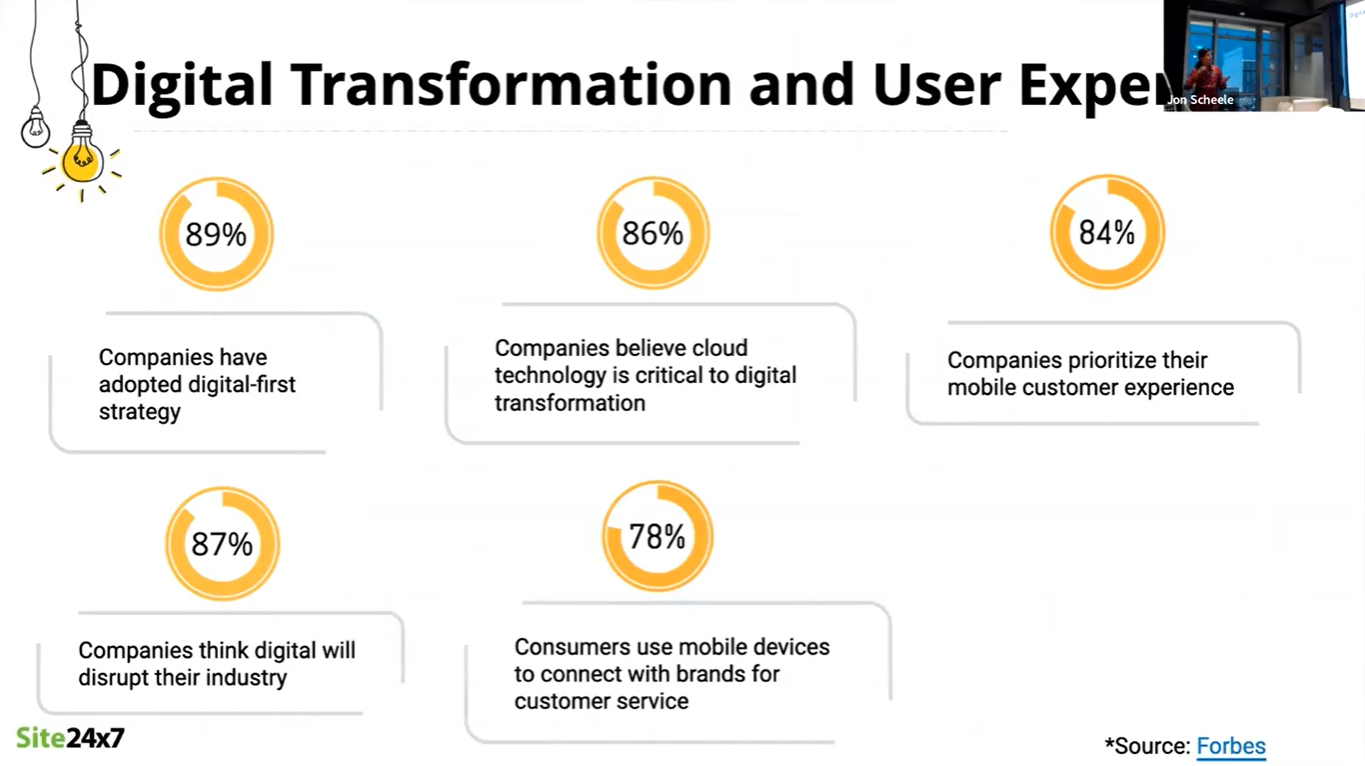
Companies are now prioritising digital transformation and the customer experience:
- 87% of companies think that digital will transform their industry
- 78% of consumers use mobile devices to connect with brands and companies for customer service
- 84% of companies prioritise their mobile customer experience
- 89% of companies have adopted a digital-first strategy
- 86% of companies believe that cloud technology is critical to digital transformation
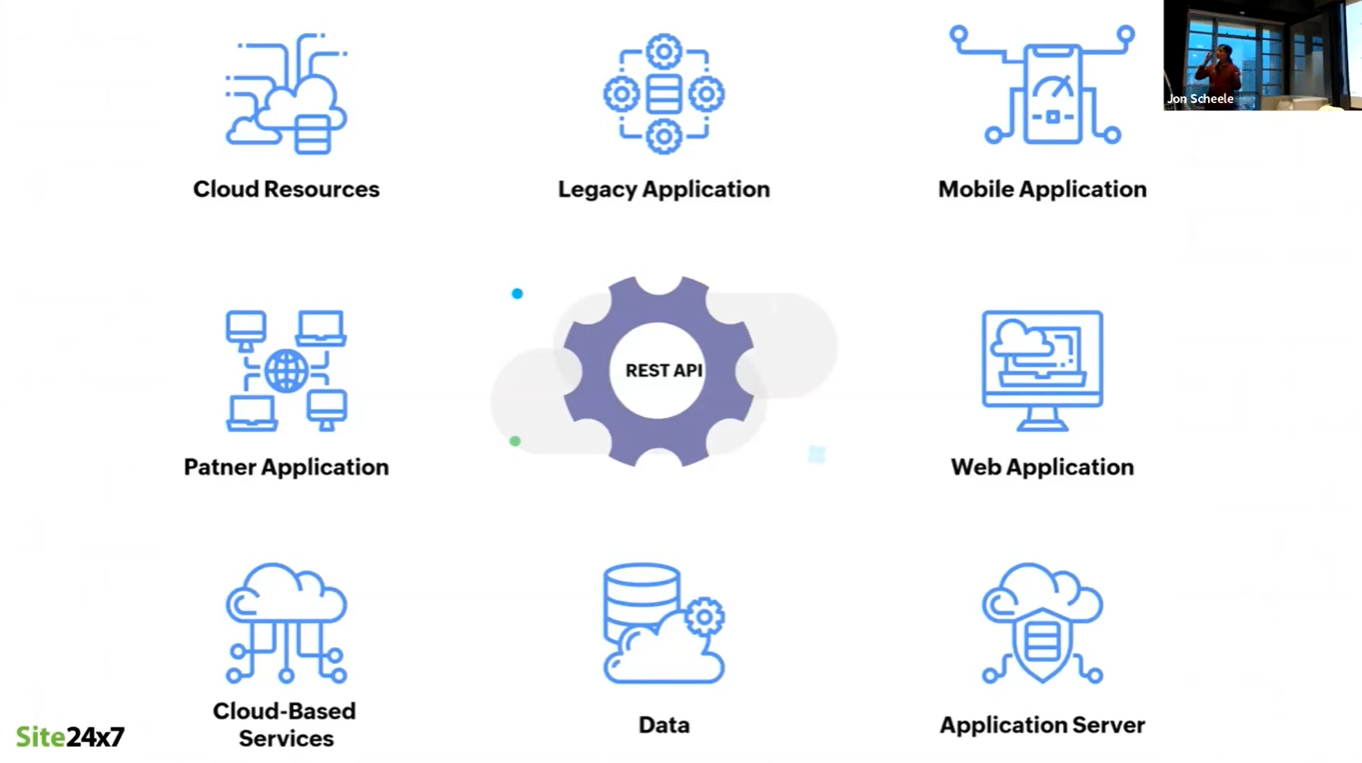
APIs are the glue that connect services
Making seamless customer experience possible is the connection between systems afforded by APIs. APIs connect:
- Application servers
- Web applications
- Mobile applications
- Legacy applications
- Data
- Cloud resources
- Partner applications
- Cloud-based services
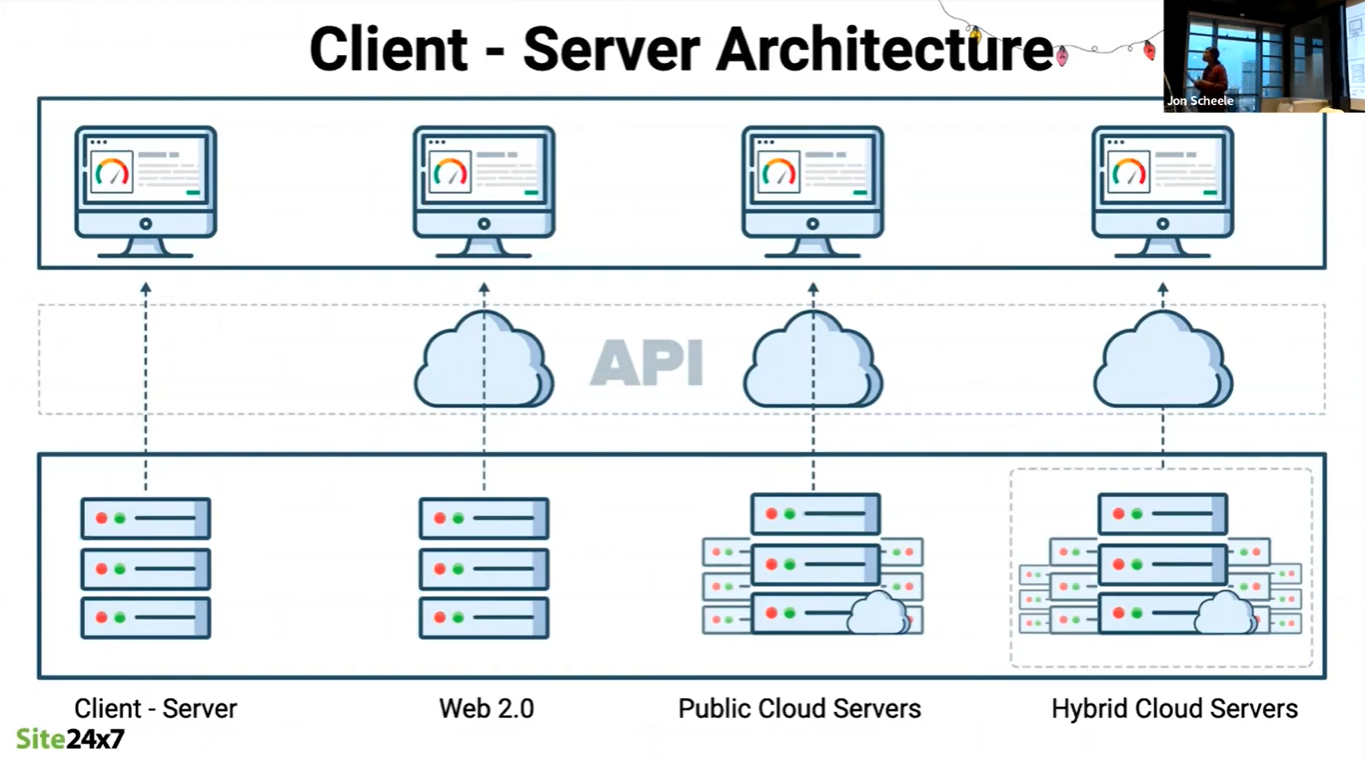
API stack in a cloud architecture
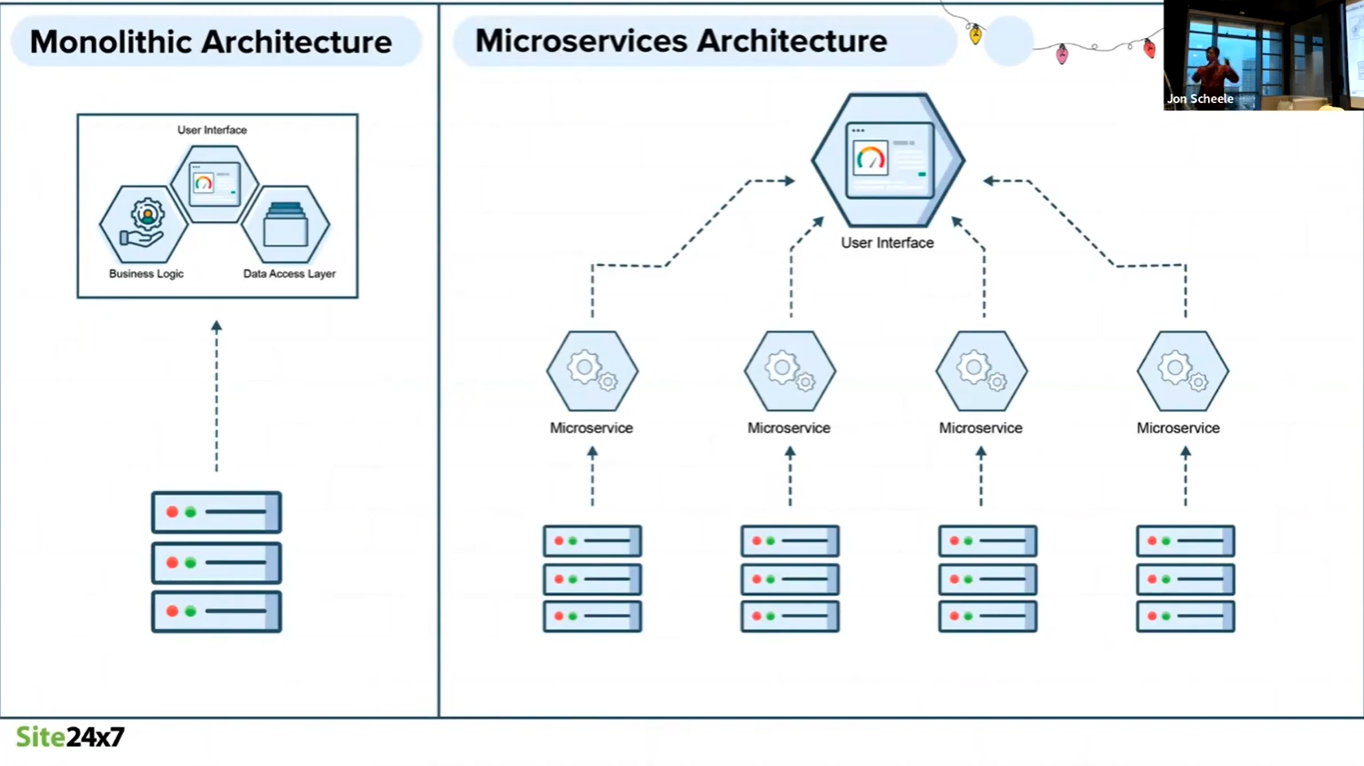
The classic client-server architecture has been the most popular architecture for some time.
In this architecture, APIs provide the link between the client and server tiers.
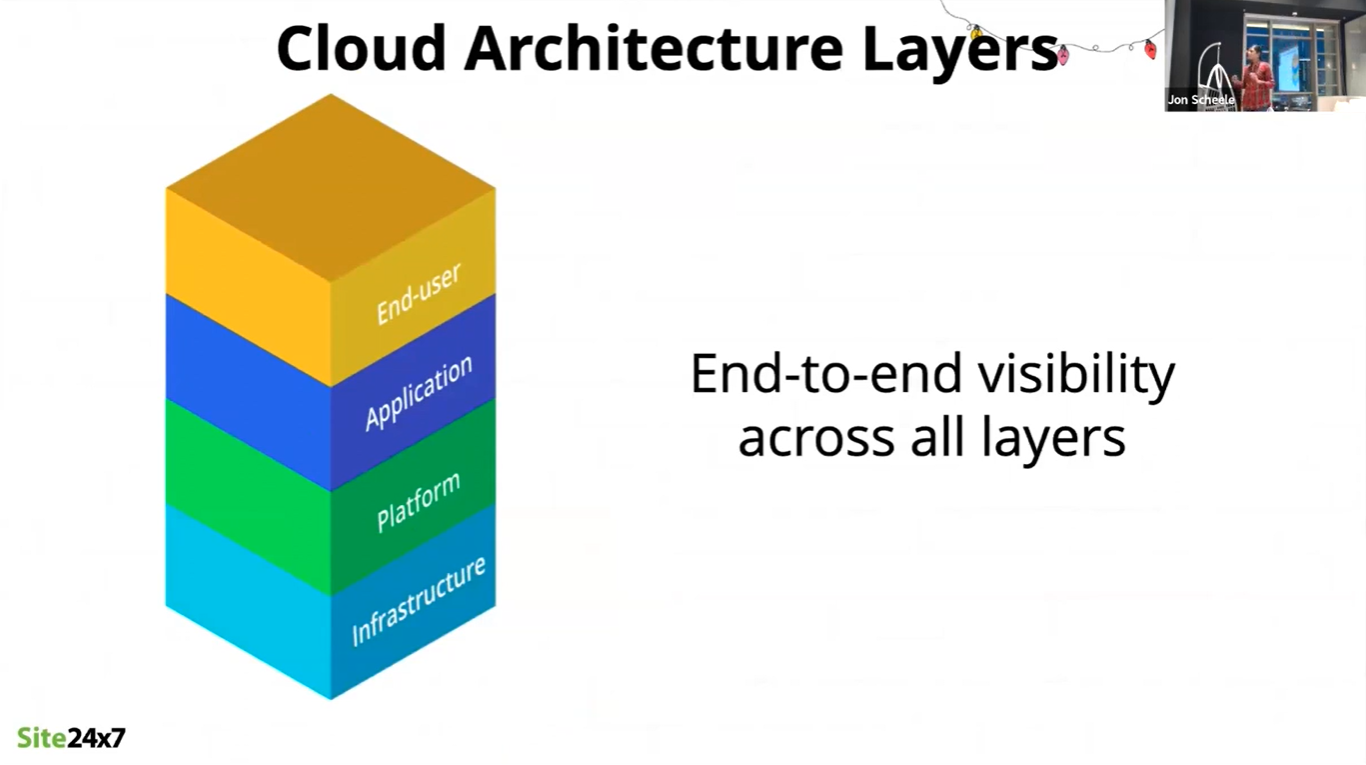
Cloud computing enables greater availability and scalability of resources. This also enables greater specialisation, and the adoption of a more layered architecture. Communication between the layers is afforded through APIs.
As large monolithic applications have become increasingly difficult to modify, maintain and extend, there has been a significant shift to microservices: smaller, specialised applications that are assembled as building blocks of a larger, end-to-end service.
The flexibility and re-usability of microservice-based architectures is made possible by the communications between microservices through APIs.
Observability vs Monitoring
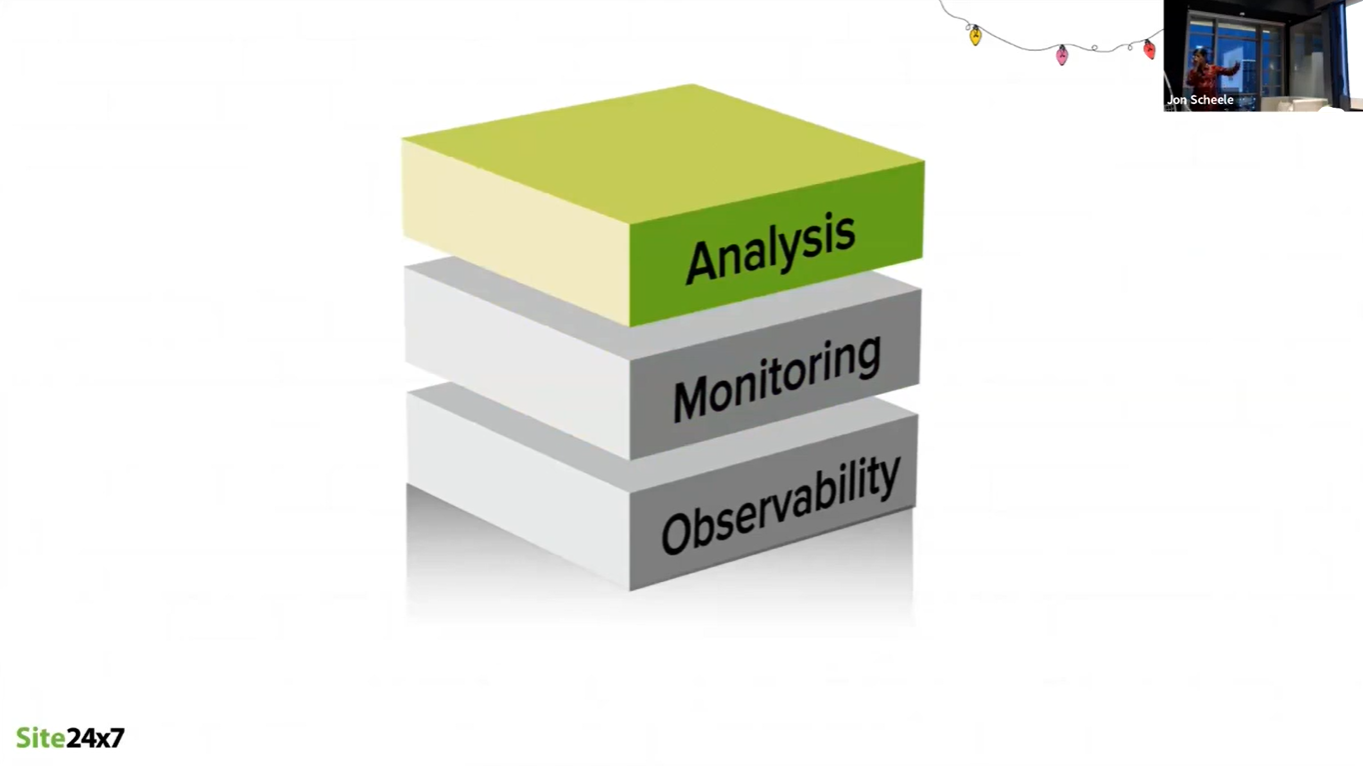
A great customer experience depends on a scalable, connected archtecture. But this is not "set and forget". Once the service is live, every element must be monitored constantly to ensure high-performance and high-availability.
Observability is the foundation on which monitoring and analysis are built. Each building block of the service, whether in a client-server, cloud or microservices architecture, must be able to expose the status and throughput to the monitoring applications. Monitoring must in turn be analysed to ensure meeting of customer expectations, conformance to Service Level Agreements (SLAs), or to warn of potential problems.
DevOps and SRE and Observability
Monitoring and analysis of system performance and availability is the concern of both Developers and Operations staff. Each has a particular focus.
Developers are concerned about:
- Application: minimising latency of the application itself
- End-user experience: minimising end-to-end latency
- Quality: ensuring new releases don't degrade performance
- Code-level errors: finding root causes sooner

For Operations teams, the focus is:
- Application: ensuring the application is available and meets SLAs
- Performance: being able to correlate infrastructure and application metrics
- End-user experience: find and fix problems before users complain
- Benchmarking: understand baseline performance to focus trouble-shooting

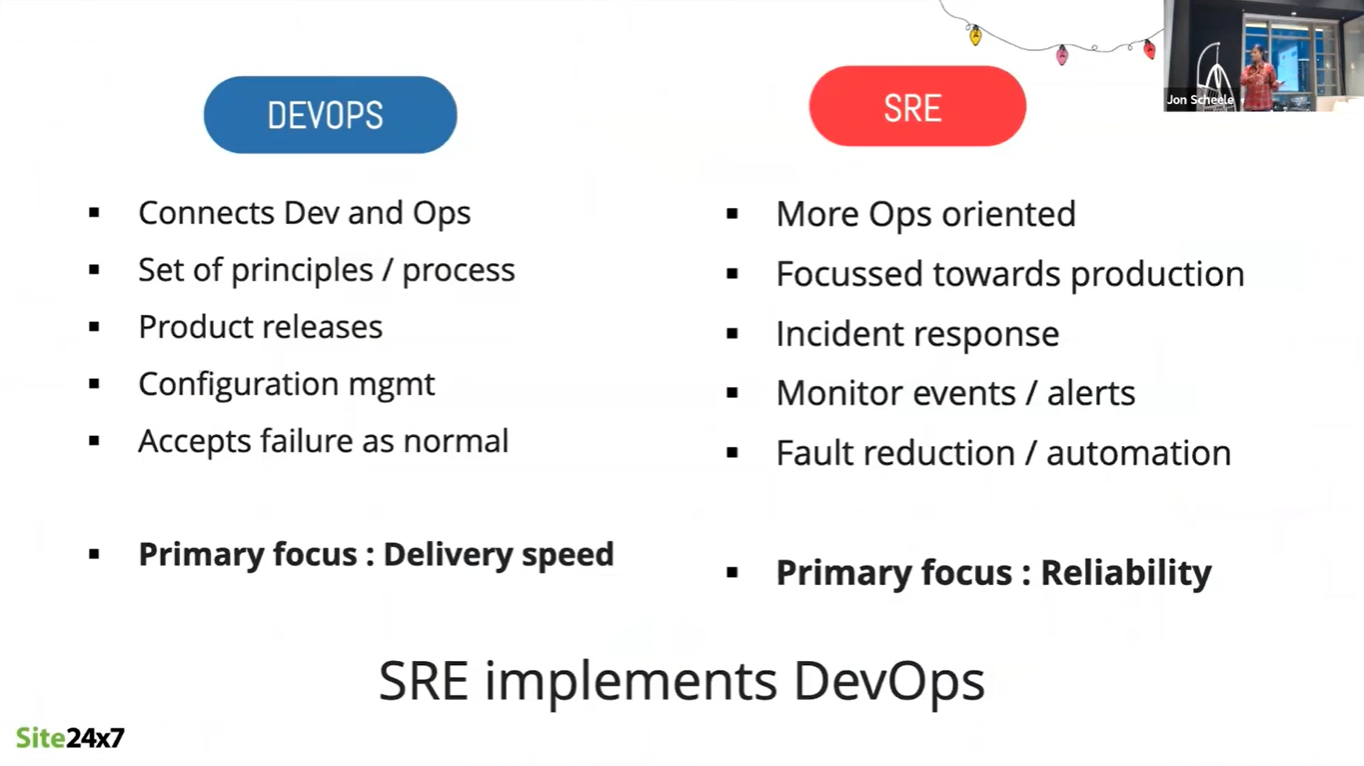
The difference between DevOps and Site Reliability Engineering (SRE) is that DevOps is primarily focused on delivery speed, while SRE, as the name suggests, is primarily focused on reliability. Security is a common concern of both.
Three pillars of Observability
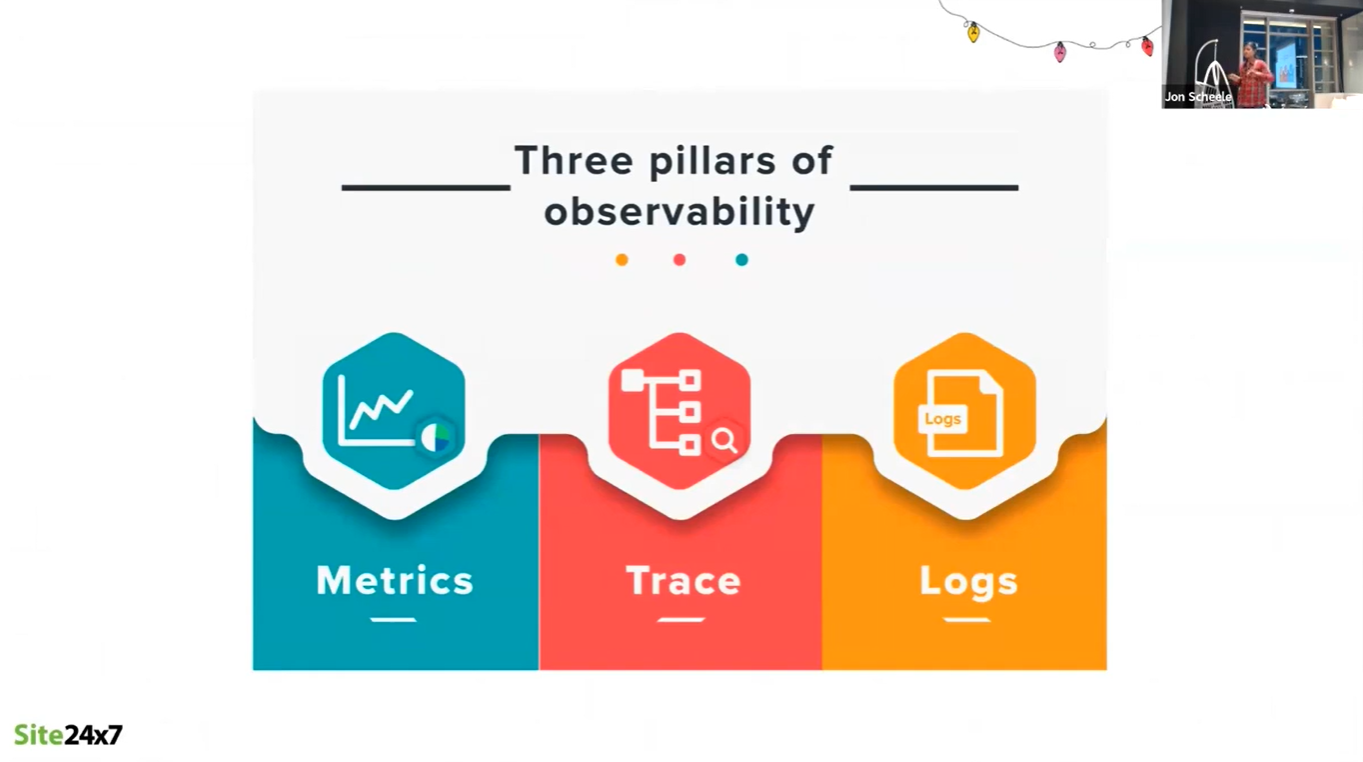
The three pillars of Observability are:
- Metrics
- Tracing, and
- Logs
Metrics
Every organisation will identify metrics specific to their use case, but common metrics include:
Availability
The industry expectation is 99.99% availability. This must carry through all components, including the API. In fact, if the API itself is not available, the service which it exposes is also not available.
Performance
Latency (the amount of time for an API or application to respond) is critical to the user experience. Very often minimising latency is more important in user-facing web or mobile applications, but there are also system-to-system communications where timing can be critical. Analysing performance, and how this may degrade under high demand, is important to ensuring that both the API and the end-to-end service meet user expectations.
Security
All endpoints must be secured. Security metrics include both successful and failed authentication, authorisation, as well as volumes of requests (and whether this is abnormal). And understanding of normal or acceptable request volumes is necessary to set appropriate rate limits (throttling).
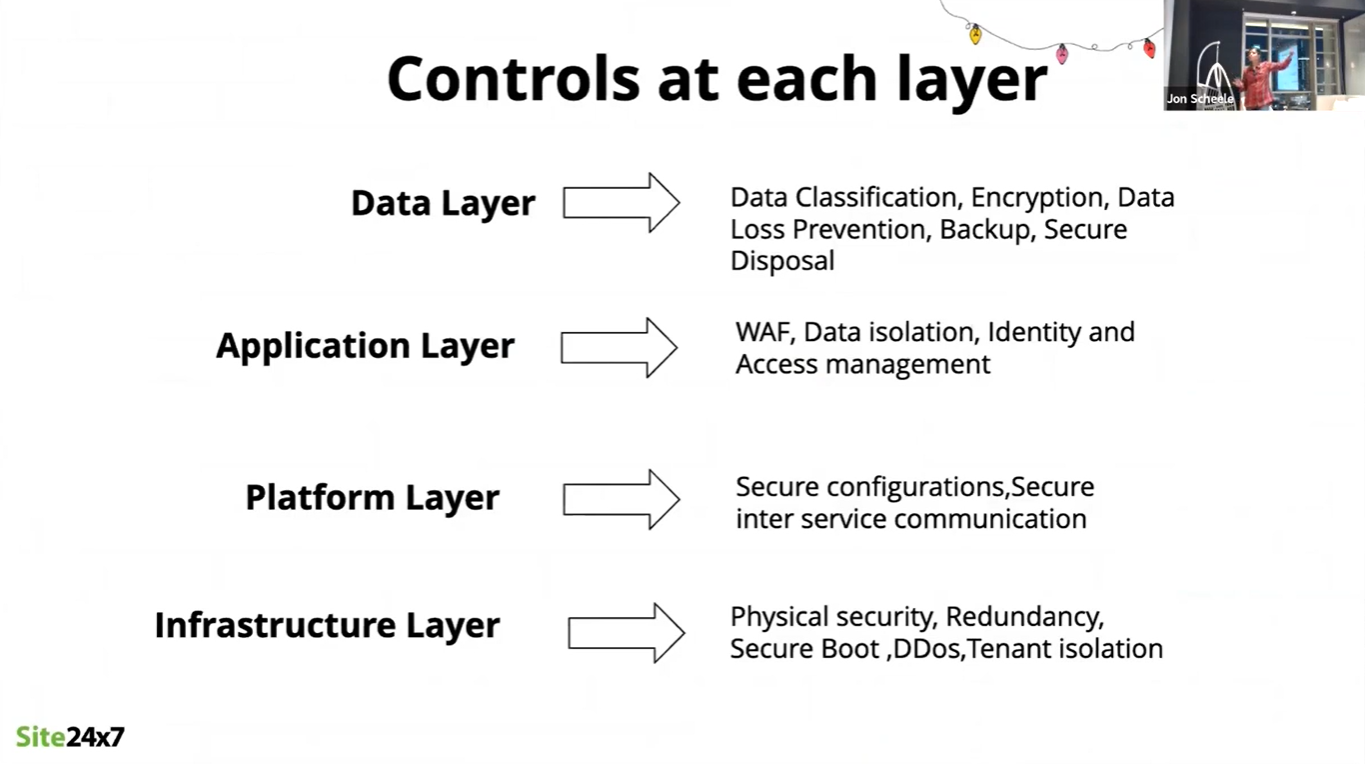
Controls
Controls are required across all layers of your service:
- Data: Ensure that data is classified properly, as well as encryption, data loss, prevention, backup and secure disposal.
- Application: Web application firewall, data isolation, identity and access management.
- Platform: Secure configurations, secure inter-process communications.
- Infrastructure: Physical security, redundancy, secure startup, protection against Distributed Denial-Of-Service (DDOS) attacks, tenant isolation.
Scalability
Ensuring that sufficient capacity is available when volumes increase or decrease requires either horizontal scaling or vertical scaling (or both). It's important to monitor the auto scaling environment to understand whether it is responding appropriately as demand fluctuates.
Costs
Whether operating on-premises or consuming cloud-based services, collecting cost metrics are key to making appropriate decisions:
- Which business units/teams are spending, and are the costs being allocated appropriately across departments?
- What resources are being used (and how much will it cost)?
- What resources are unutilized (or under-utilized)?
- How can costs be optimised?
Tracing
In any of the complex architectures mentioned above, the source of a performance or other problem could lie in any of the layers. Moreover, end-to-end interactions or transactions traverse all of them, so the effect on the end-user experience can be impacted by any one of them.
Whether to address high latency, or to trouble-shoot an error, identifying the root cause requires tracing across all the layers. Adding to this complexity is the challenge that some issues will happen only in the production environment. As much as certain conditions can be simulated in testing, the actions of real users, and the interplay of different applications under changing internal and external conditions mean that Application Performance Management (APM) tools must be adapted to trace activity across the ecosystem.
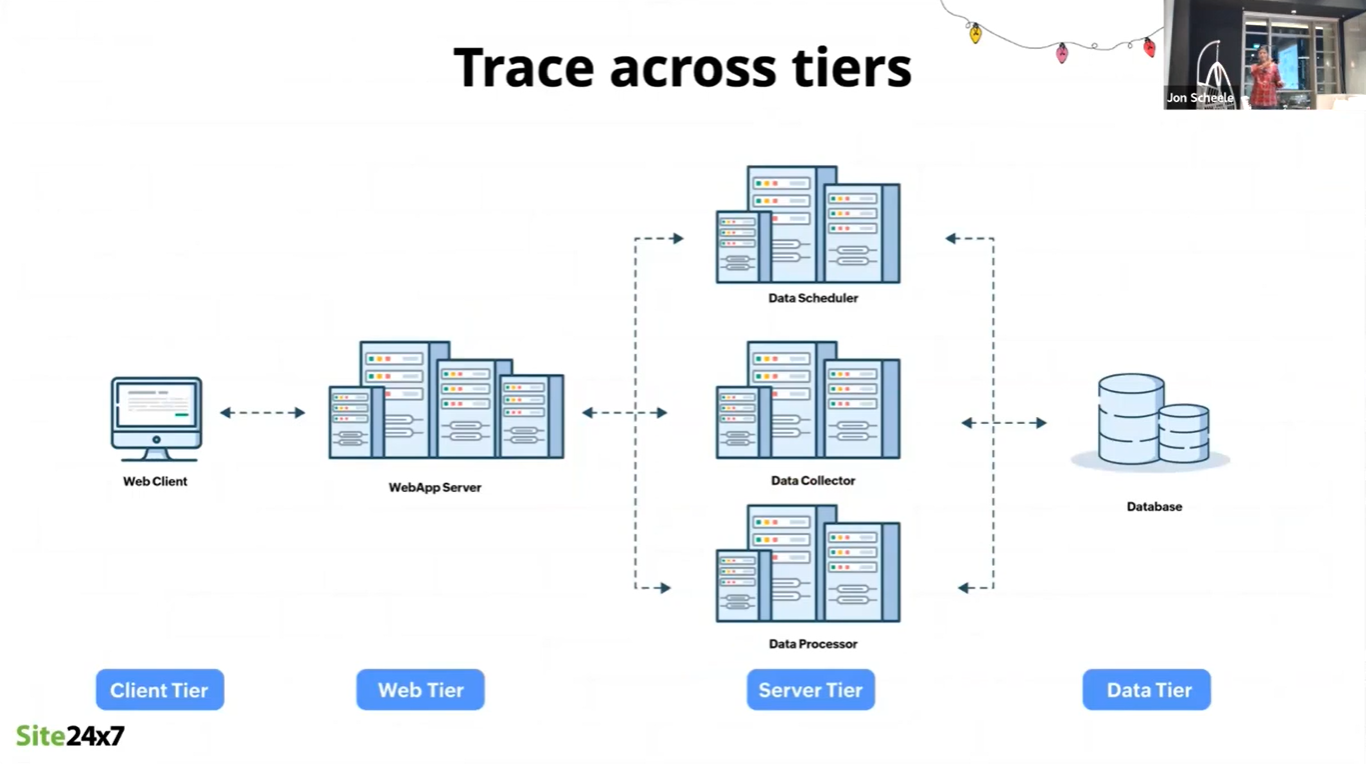
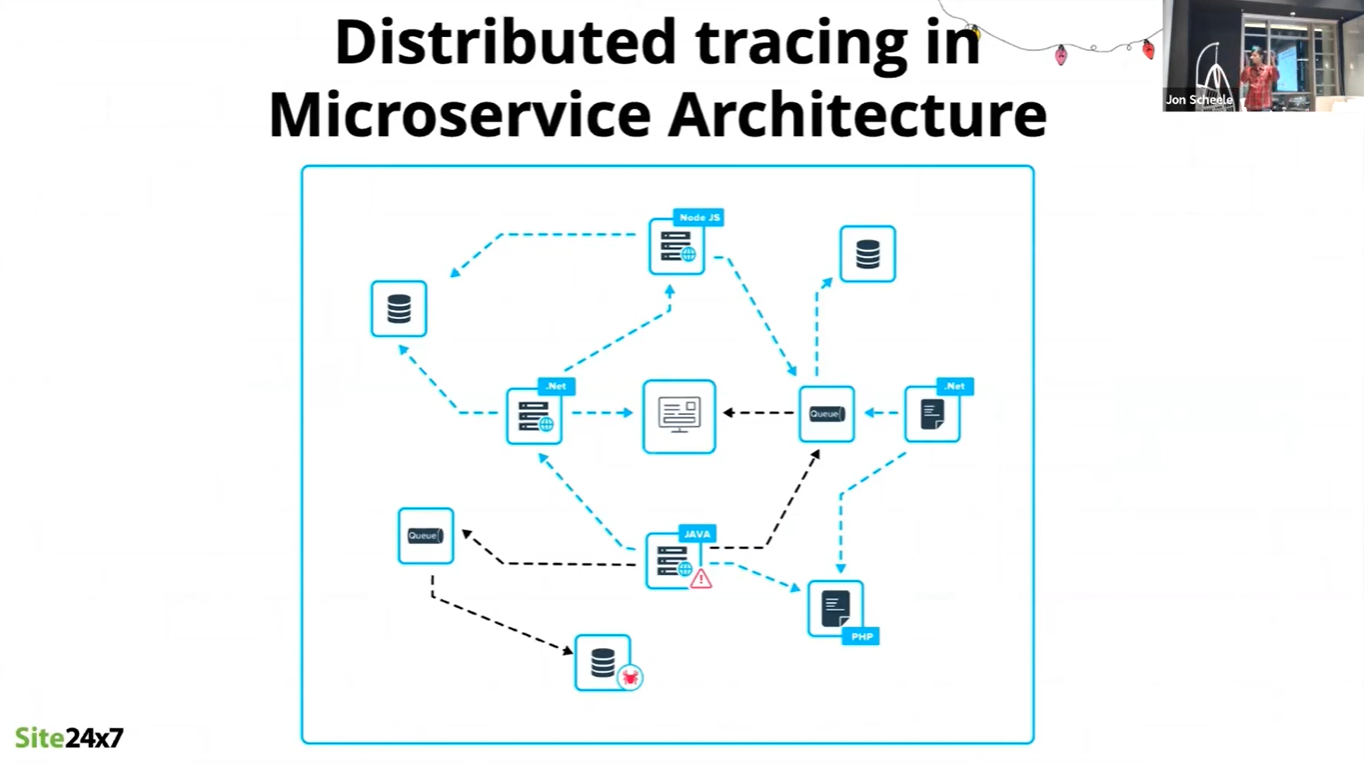
This is particularly challenging in distributed environments such as microservices architectures, where each of microservice may be running in a different programming language, different operating system, or even on the other side of an organisational boundary.
So the organisation of a tracing capability, and the tooling used, must accomodate multiple technologies, application and infrastructure types. It must also have connectivity and appropriate permissions to access monitoring information from multiple environments.
Logs
After the identification of metrics and scenarios to be traced, data must be sourced from the applications and systems being monitored. This requires the collection of logs from a wide variety of sources, including:
- Applications
- Databases
- Operating systems
- Network devices
- Access logs
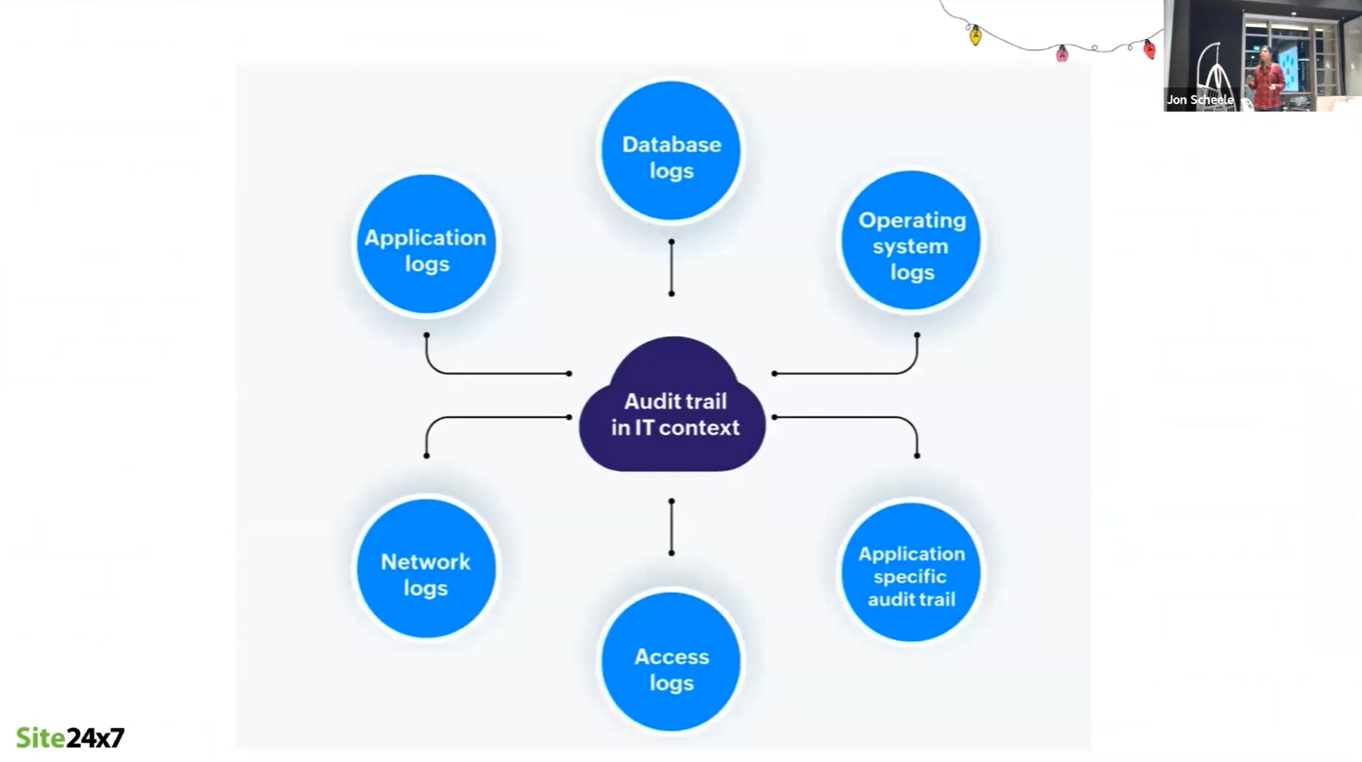
Because of the variety and different technologies of these sources, data must be collected, consolidated, correlated and transformed in order to be useful for analysis.
There is also a wide variety of users of this analysis: Developers, Operators, Managers, Finance. Each requires specific information in a specific form in order to make decisions. As with other data-related decision-making, data collection must address all these elements.
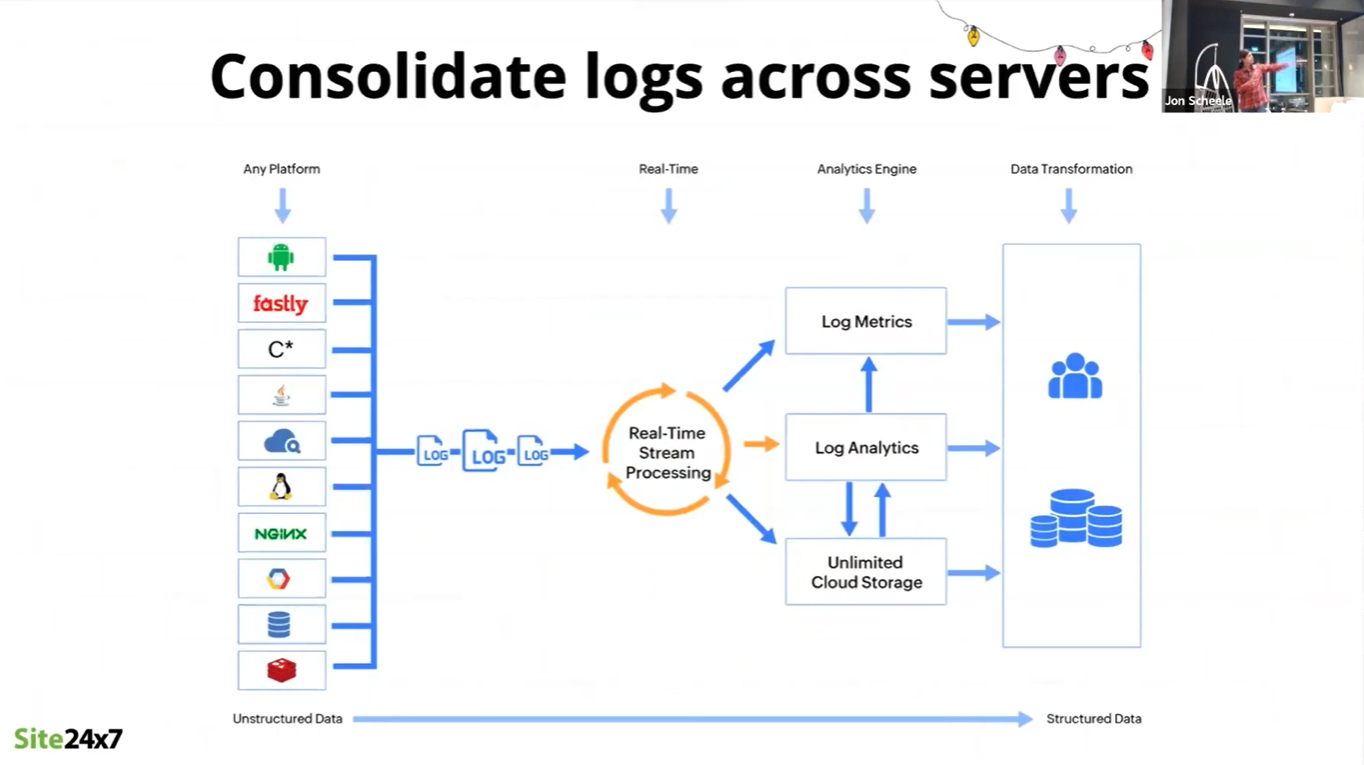
Putting it all together
Heightened customer expectations, and organisations' digital transformation efforts, has made APIs a critical component of service and value delivery.
Effective monitoring capabilities enable the management of API performance to meet these expectations.
But this is not a "set and forget" activity. As with other technologies, API performance management is subject to "The Red Queen problem": that we must constantly adapt, evolve in order to survive (source: https://en.wikipedia.org/wiki/Red_Queen_hypothesis)

About Rajalakshmi Srinivasan
Rajalakshmi "Raji" Srinivasan is the Director of Product Management for Site24x7 at ZohoCorp.
Watch the recording of Raji's presentation
Watch Raji's full presentation here: